存储介质
- 磁: 磁铁方向, 磁盘
- 光: 挖坑填坑, 光盘
- 电: SSD
- 存储介质相当于是一个字节数组
bool bits[CAPACITY];
I/O设备与驱动
- I/O设备: 设备是三种操作的集合:
- (别人)发送命令(给他)、(别人)读取(他的)状态、(互相)传输数据
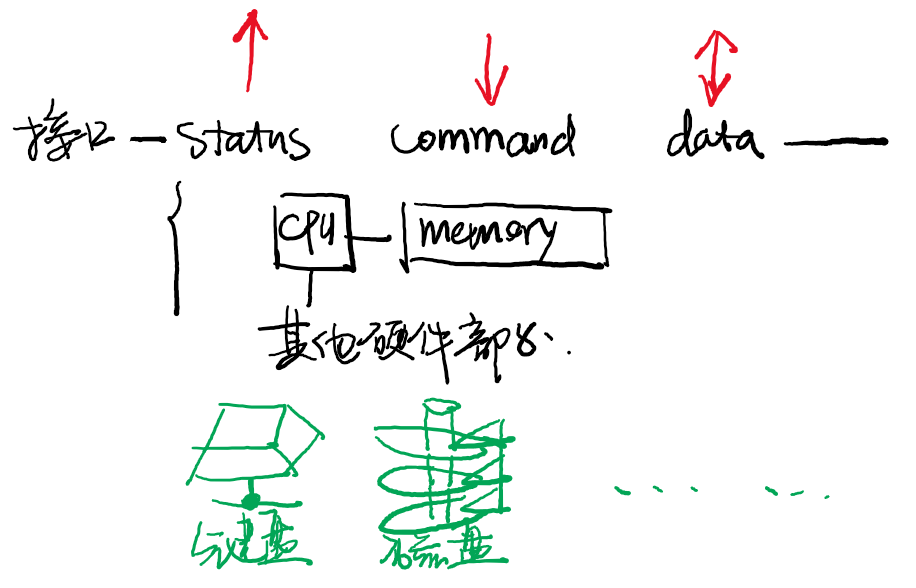
键盘: 按键信息会存储到键盘内置的缓冲数据区
缓冲区通常大小是有限的
如果缓冲区满,后续按键将会丢失 (可能会发出声音)
1
2
3
4
5
6
7
8
9
10int status = inb(0x64);
if ((status & 0x1) == 0) {
// no input
} else {
if (status & 0x20) { // mouse
} else {
int code = inb(0x60) & 0xff;
// 按键的“扫描码”
}
}
磁盘: 磁盘是一个巨大的bit array
磁盘控制器: 配置好需要读/写的位置,然后开始传送数据
1
2
3
4
5
6
7
8
9
10
11
12
13void waitdisk(void) { while ((in_byte(0x1F7)&0xC0) != 0x40); }
void readsect(volatile void *dst, int sect) {
waitdisk();
out_byte(0x1F2, 1); // 读sector的数量
out_byte(0x1F3, sect);
out_byte(0x1F4, sect >> 8);
out_byte(0x1F5, sect >> 16);
out_byte(0x1F6, (sect >> 24) | 0xE0);
out_byte(0x1F7, 0x20);
waitdisk();
for (int i = 0; i < SECTSIZE / 4; i ++)
((uint32_t *)dst)[i] = in_long(0x1F0);
}
I/O设备: 实现
- CPU终究是通过地址和数据访问I/O设备的
- Port IO/MMIO只是两种不同的地址空间
- 电路负责根据地址把地址和数据“转发”给设备
- CPU终究是通过地址和数据访问I/O设备的
显示加速器(显卡GPU)
- GPU是一个“协处理器”
- CPU可以将代码和数据传输给GPU
- GPU执行程序,并且可以将程序的一部分输出绘制到屏幕上
- GPU是一个“协处理器”
管理I/O设备
- cat /proc/iomem: 得到IO的内存映射
- lspci: 查看总线上的设备
- lsblk: 查看块设备
- “回路”设备
- 可以把一个文件模拟成一个块设备
- mount后在lsblk中可以看到
- 用代码访问I/O设备:
- 等待设备空闲
- 给设备发送数据和命令
- 等待设备完成命令
- 拒绝忙等待: 利用中断机制
- 在设备完成请求/发生变化时通知处理器
- 例子:磁盘可以配置成“命令完成后发送中断”
- 例子:再也不需要轮询键盘,有按键按下后会收到键盘中断
抽象层: 设备驱动(以Lab2为例)
设备驱动: os中负责与设备交互的程序. 根据设备类型不同, 给每一类设备以统一的接口访问, 实现这个接口的就是设备驱动程序.
从系统启动后就一直存在
简化了很多(Plug and Play非常麻烦)
每个设备有三个操作:初始化、读、写
1
2
3
4
5
6
7
8
9typedef struct device device_t;
typedef struct devops {
int (*init)(device_t *dev);
ssize_t (*read)(device_t *dev, off_t offset, void *buf, size_t count);
ssize_t (*write)(device_t *dev, off_t offset, const void *buf, size_t count);
} devops_t;
typedef struct {
void (*init)();
} MODULE(dev);
DMA:可以理解为实现
memcpy()的I/O设备性能不够, 处理器来凑
文件系统
文件系统概念
磁盘 (I/O设备):一个可以读/写的定长字节序列
- 虚拟磁盘(文件):一个可以读/写/的动态字节序列
- 可以理解成
std::vector<uint8_t> - 类比
- 进程 (虚拟CPU):分时共享一个CPU
- 虚拟存储:多个虚拟地址空间
文件: 理解成一个名为xxx的虚拟存储设备(磁盘),我们可以对这个虚拟磁盘中执行写入数据、扩展大小等操作
目录directory: 文件/目录的集合
- 目录体现了局部性:相关的数据存放在相近的目录
- 目录结构: 树形结构有助于帮我们分组
- 人工训练的一个“决策树”
- 每个目录有
.(当前目录)和..(上级目录)两个特殊的目录
目录/文件(inode)
- inode number: 索引数
文件系统是保存在持久存储上的数据结构
- 数据结构在磁盘上的存储格式规范
- 允许对数据结构进行的操作
- 文件系统实现 = 数据结构的查询/修改操作
- 可以通过文件管理进程(能够访问存储设备)实现
- 文件系统基本操作
- 目录操作:
- 改变进程工作目录(chdir)、路径解析(当前目录pwd)
- 读取目录 (getdents)
- 目录操作 (link, unlink, rename, …)
- 文件操作:
- 打开(返回文件描述符)、关闭
- 文件描述符操作:read, write, lseek, ioctl, mmap, …
- 目录操作:
文件意义扩展: 操作系统中的一个可读/写/控制的对象
- 文件描述符:指向操作系统对象的handle(指向对象的指针)
- read/write/ioctl系统调用 = 对象访问
- 虚拟文件系统
- 需要实现的需求:
- 根据路径解析出操作系统中的对象 (磁盘文件、进程、操作系统配置、……)
- open() → 解析路径、找到对象 → 对象自带read/write/…操作 → 创建文件描述符
- 实现:
- 把read/write翻译成对操作系统对象的读写, 包括进程/线程, 文件/目录, 设备, 其他数据
- 需要实现的需求:
文件系统API
挂载
- procfs, sysfs都不是系统启动自带的,而是“挂载”的
- 系统启动后仅有
/,/dev,以及initramfs中的少量文件 - init程序负责挂载其他部分(例如
/home)
- 系统启动后仅有
挂载机制创建了文件系统世界:连接设备 - 文件系统实现 - 目录树
mount -t type device dir
系统中允许
- 有多个文件系统根“/”,互相不可见
- chroot; 容器 (namespaces)
- chroot只影响路径解析, 如果持有外部文件描述符,则很容易jail break
- 如果“everything is a file”,所有可见的东西都在文件系统里,那么改变文件系统root就实现了完全的隔离
- chroot; 容器 (namespaces)
- 一份文件系统代码,多个设备/挂载点
- 允许系统内有多个ext4分区
- 挂载多个procfs/sysfs (容器)
- 把一个文件(例如.iso)挂载到文件系统中
- 通过loopback device (类似于“虚拟光驱”)
- 有多个文件系统根“/”,互相不可见
目录管理
- 目录也存储数据 (字节序列),也是虚拟磁盘,因此目录和文件都用“inode”表示 (一个编号)
- 操作系统在路径解析、目录遍历时对它的数据有特殊的解读
- 实现方法:目录上有一些额外的操作
- lookup (路径解析)
- create (创建文件)
- link (链接)
- unlink (删除)
- 目录: 并不是树!
- Linux系统允许创建两种类型的链接
- 硬链接:hard link
- 目标只能是文件, 不能是目录
- 不能跨文件系统
- 硬链接总是合法可以访问——能看到硬链接,说明文件系统被挂载
- 软(符号)链接:soft/symbolic link
- 符号链接可以是任何相对/绝对路径
- 只是一个“路径解析提示”
- 非常有用 & 容易滥用
- 符号链接可以是任何相对/绝对路径
- 硬链接:hard link
文件管理:打开文件
- 我们熟知的一系列API,访问各种文件:
- open(); read/write(); close();
- 用这套API:
- 访问磁盘上的数据
- 读取系统信息 (procfs)
- 配置操作系统 (sysfs)
- …
打开目录
- 目录可以open但是不能read write
- 打开目录得到了一个指向文件系统某个位置的指针
- 对目录本身的操作
- fchmod, fchown, …
- 相对于目录位置的操作
- openat()
- linkat()
- 更多的好处
- 避免了每次open都解析路径 (有时路径很长)
- 在fd在合法的前提下,目录总是存在
文件描述符
对同一个文件的多次操作是自然的
- 文件描述符避免了每次操作都要重新打开文件
- 同时也帮助我们自动管理文件访问的偏移量
内存映射方式访问
- 适合随机访问的结构数据 (数据库)
- mmap
- 或read/write方式访问
- 适合流式文件 (文件描述符托管了offset)
保存文件
- 执行
sync命令, 将缓存中磁盘操作都写入磁盘
文件系统实现
- 文件系统是支持文件和目录操作的数据结构
- 文件实现磁盘的虚拟化
- 目录实现文件的分类归档
块设备
块设备 = 固定大小的块(block)的数组 (存储设备);支持:
- read(#blk, data)
- write(#blk, data)
- 查看块大小
blockdev --getbsz /dev/sda2(通常4KB) (通过sysfs得知)
块设备API:
- 进程/线程(通常是文件系统实现)向存储设备提交I/O request (block读/写)
- request首先进入设备的队列
- 经过调度器调度后,执行设备上的I/O (DMA)
- 调度是为了
- 保证多进程之间的公平性/优先级
- I/O操作的合并
- 进程/线程(通常是文件系统实现)向存储设备提交I/O request (block读/写)
Block I/O调度
- I/O请求优化 + 兼顾进程优先级和公平
- 例子:按照“电梯”方式寻道
- 不该归操作系统管
- I/O请求优化 + 兼顾进程优先级和公平
实现文件系统1: 虚拟磁盘
文件 = 虚拟的磁盘
- 数据块的数组,支持read, write, lseek操作
- 元数据 (大小固定):大小、访问权限、修改时间……
链表或树实现:
- 只需要balloc()和bfree()
在磁盘里划分一块专门的区域,每个bit代表每个块是否可用
实现文件系统2: 目录文件
- 首先,假设系统里的每个文件(虚拟磁盘)都有唯一的编号(id)
- 稍后我们讨论如何维护这个编号
- 目录 = 文件名 → 文件id的映射 (这个机制天然支持链接)
目录也是文件
- 用文件(虚拟磁盘)来存储key-value mapping
- 支持以下操作:
value = get(key)(路径解析)set(key, value)(link)delete(key)(unlink)get_keys()(遍历目录中的文件)
把虚拟磁盘看成
_heap = { start, end }- 实现目录文件就是OSLab1 (…)
- 额外需求:
get_keys(),get()应当高效
实现文件系统3: 元数据inode
我们希望文件有
唯一的一个编号
元数据
信息
- 类型:是否为目录
- 数据:大小、权限、访问时间、链接数量
- 链表实现:链表的第一个块;树实现:索引块的编号
UNIX:每个文件用一个inode (index node)表示
ls -i可以查看inode编号;stat查看文件元数据
元数据inode的存储
- 单独区域
- 文件id = inode编号
目录文件中
- 文件id = 文件的第一块编号
文件头部
- 文件id = 文件的第一块编号
- 单独区域
实现文件系统
- 实现文件系统需要考虑以下因素:
- 虚拟磁盘的数据结构 (链表、树、……)
- 目录文件的数据结构
- inode的表示和存储
- balloc/bfree的实现
FAT和ext2
问题分析
- 实现文件: 链表, 为每一个block都维护一个“next block”
- 链接存储在块尾
- 统一存储链接
- File Allocation Table文件分配表, 集中存储next
- next block占多少个字节? FAT32 → 32bit (绝大部分信息都是32bit)
- 存储在文件系统头部, super block后
FAT32
FAT文件系统的基本思想是使用链表管理所有的数据块。FAT文件系统把若干个连续的扇区(sector)作为一个簇(cluster),也就是我们所说的管理存储的基本单位“块”,因此如果我们希望表示一个文件,我们只需要知道:
- 文件的第一块的编号
- 对于每一块,它下一块的编号
因此,FAT文件系统专门在磁盘中开辟一个区域(File Allocation Table, FAT),来存储每一块的下一块编号。除了编号之外,还有两种特殊的编号:
- free (0, 该块可以使用)
- EOF (-1, 该块代表了某个文件的末尾)
这样,FAT还可以兼用于block bitmap,用于分配/回收数据块。
Partition Boot Record(PBR), 存储在分区的头部(例如
/dev/sda1)block”在FAT32中称为“sector”的“cluster” (簇)

文件分配表
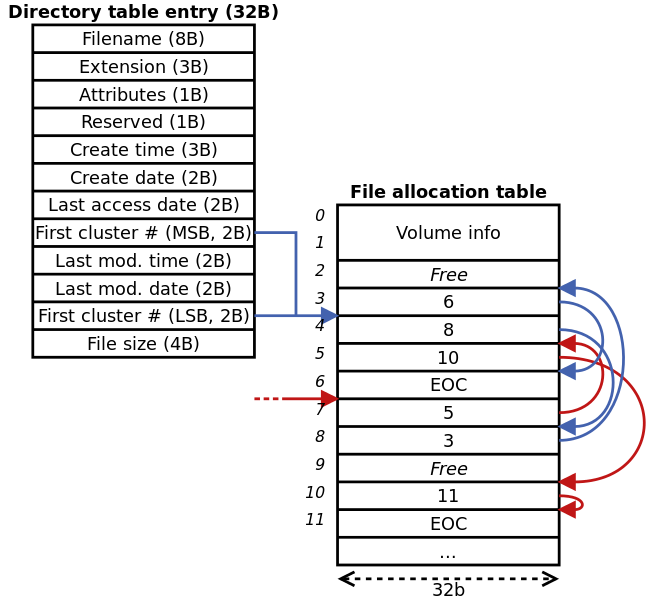
FAT32目录项
- 不支持链接; 因此inode(元数据)直接存储在目录项中
- 目录项直接按顺序存储在文件中
- FAT16:11字节文件名(8文件名+3扩展名);向前兼容

FAT如果损坏将会导致非常严重的后果
- 相当于链表所有的“next”都丢失了
- 解决办法:多份FAT备份 (PBR)中指定了“number of FATs”
- 通常有两个副本,同时更新
文件系统可能碎片化
- 磁盘碎片整理
- 在磁盘中进行数据的“腾挪”
- 使文件尽可能在磁盘中占有连续的块
ext2文件系统
实现文件: 索引
文件小的时候,立即能找到它的块
文件大的时候,才用索引
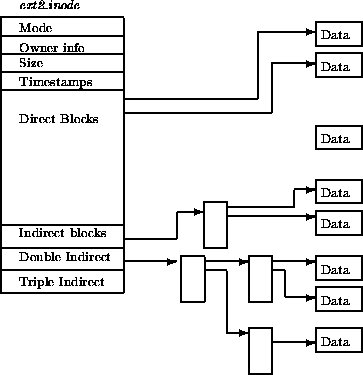
支持链接,因此ext2单独管理inodes
- 每个inode占用128B或256B空间 (相比FAT来说是很大的)
- 相比于FAT来说,浪费少量空间
tune2fs -l /dev/sda1- 查看文件系统信息
- 每个inode占用128B或256B空间 (相比FAT来说是很大的)
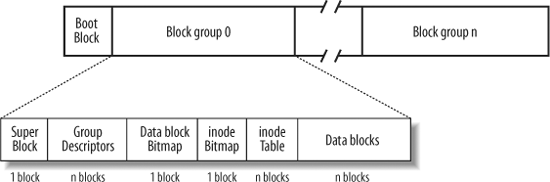
- 为什么要分组?
- 把分配分为成了两级 (组级、块级)
- 不用管理全局的bitmaps (inode/block)
- 一定程度的性能优化
- 尽量把相近(例如同一个目录)的文件分配在同一个组里
- 尽量把同一个文件的数据块分配在同一个组里
- 这个设计还使磁盘大小动态调整变得容易
- 对于小文件(12个块以内,4KB块是48KB),直接索引,没有额外的空间开销
- 对于中等文件,只使用一级索引
- 对于更大的文件(但更少),使用更多级别的索引
- 把分配分为成了两级 (组级、块级)
- 与FAT类似,ext2的目录中按顺序存储其中文件/子目录的名字和inode编号。
我理解的FAT和ext2的区别:
- ext2的inode集中储存, 而FAT的存在目录项中, 因此不支持链接
- 对于单个文件, FAT是用链表链接的, 每一块的下一个存在文件分配表中; 而ext2是树状结构
持久数据可靠性
RAID: 创建副本
- 廉价冗余磁盘阵列
把多个磁盘虚拟成一块磁盘
用两块磁盘(redundancy)实现容错
read(blk)-> 从任何一块盘读即可write(blk)-> 必须写入两块磁盘- 实现了2X读速度
- 写速度不变
- 可以抵抗一块盘损坏 (只要磁盘没有连续损坏,就能实现容错)
- 设计RAID,就是设计“如何把虚拟磁盘块映射到物理磁盘块”
- 允许一对多映射; redundancy冗余
- 评价标准: capacity, reliablity, performance
RAID-0(Striping) = 没有冗余
- 无冗余, 不容错, 性能2X、容量2倍, 连续的块轮流分布在不同的Disk上(加快连续读写速度)
- 和chunk size有关, 小了读写的并行性增加, 但是跨越chunk读取可能性增加, 增加了access时间
RAID-1:(mirror)
维护两块数据完全一样的磁盘实现容错
纠错码:
- 无论有多少bit,只要至多只有1位错,我们就可以用1bit来纠错
- 存储x, y, z, x\oplus y\oplus zx,y,z,x⊕y⊕z
- 任何一个数值丢失,都能恢复出剩下的
- 无论有多少bit,只要至多只有1位错,我们就可以用1bit来纠错
RAID-4(奇偶校验)
| Block | 磁盘1 | 磁盘2 | 磁盘3 | 磁盘4 | 磁盘P |
|---|---|---|---|---|---|
| #0 | 0 | 1 | 2 | 3 | 0⊕1⊕2⊕3 |
| #1 | 4 | 5 | 6 | 7 | 4⊕5⊕6⊕7 |
| #2 | 8 | 9 | 10 | 11 | 8⊕9⊕10⊕11 |
| #3 | 12 | 13 | 14 | 15 | 12⊕13⊕14⊕15 |
5块盘实现:
顺序/随机读 4X加速
顺序写入依然可以4X
随机写入:
P′=P⊕D′⊕D(1的个数奇偶)
- 需要读出D和P;计算后再写入
- 速度减半
恢复一块盘: 其他盘异或
RAID-5
Parity盘是整个系统的瓶颈!因此将Party盘分散开.
| Block | 磁盘1 | 磁盘2 | 磁盘3 | 磁盘4 | 磁盘P |
|---|---|---|---|---|---|
| #0 | 0 | 1 | 2 | 3 | P |
| #1 | 4 | 5 | 6 | P | 7 |
| #2 | 8 | 9 | P | 10 | 11 |
| #3 | 12 | P | 13 | 14 | 15 |
顺序/随机读 4X加速
顺序写入依然4X
随机写入:
P′=P⊕D′⊕D
- 依然需要2读2写
理论分析
假设有n块组成RAID
| RAID | 容量 | 容错 | 顺序读 | 随机读 | 顺序写 | 随机写 |
| :—: | :—: | :——: | :——-: | :——: | :——: | :——: |
| 0 | n | 0 | n | n | n | n |
| 1 | n/2 | 1..n/2 | $>$ n/2 | n | n/2 | n/2 |
| 4 | n-1 | 1 | n-1 | n-1 | n-1 | 1/2 |
| 5 | n-1 | 1 | n-1 | n | n-1 | n/4 |
崩溃恢复和日志
磁盘上的数据结构
- 考虑在FAT上创建一个目录(mkdir)的Access Path:
- b $\leftarrow$ balloc(),读取FAT
- FAT[b]$ \leftarrow$ EOF
- 写入bb为初始数据
- 追加写入目录文件 (假设目录文件需要一个额外的数据块)
- b’$ \leftarrow$ balloc()
- 写入目录文件
- FAT[b’] $\leftarrow$ EOF
- FAT[$d_{end}$] $\leftarrow$ b’
系统崩溃: 原子性的丧失
考虑更简单的例子:追加写(相当于写入目录文件)
- $FAT[b’] \leftarrow EOF$
- $data[b’] \leftarrow$ 数据
- $FAT[f_{end}] \leftarrow b’$
等同于链表操作:
1 | struct block *blk = balloc(); // 找到某个blk->next == FREE |
- 考虑所有可能崩溃的情况 (去除重复)
- $data[b’] $→ ❌ (random writes)
- $FAT[f_{end}]$ → ❌ (corrupted FAT)
- $FAT[b’]$→ ❌ (dead block/leak)
- $data[b’]$ → $FAT[f_{end}]$ → ❌ (random writes + corrupted FAT)
- $FAT[b’]$→ $data[b’]$ → ❌ (dead block x 2)
- $FAT[b’] $→ $FAT[f_{end}]$ → ❌ (corrupted file)
- $FAT[f_{end}]$→ $FAT[b’]$ → $data[b’] $✅
对于ext2, 文件追加写(一块),需要写入:
- inode (size、索引); 2. 数据bitmap; 3. 数据
可能的崩溃情况:
- \{1\} - corrupted filesystem
- \{2\} - dead block
- \{3\} - random writes
- \{1,2\}- incorrect data
- \{1,3\} - corrupted filesystem
- \{2,3\} - dead block
fsck
功能: 发现不一致并修复
步骤:
- Superblock:
- 检查superblock是否合理; 找到可能崩溃的superblock, 决定是否使用其备份
- Free blocks:
- 扫描inodes, (double)indirect blocks等, 找到已经分配过的块.
- 如果allocation bitmaps和inodes不一致, 相信inodes
- 对于inodes进行同样的检查
- inode state, inode links(计数), 备份, Bad blocks(指向非法区域的), 目录文件(尤其是.和..)
简略的为:
在文件操作时不管崩溃一致性,但在崩溃后扫描磁盘进行补救
- 扫描inodes里的所有数据块,检查bitmap的一致性
- 检查inode数据是否“看起来合法”,否则删除
- 检查链接情况 (没有链接的inode被移到lost+found目录中)
- Superblock:
日志(write-ahead logging, journaling)
更新磁盘前先记录所做操作
把操作以append only的方式记录下来
- 先写入数据 (TXBegin和数据);然后sync
- 写入TXEnd;再次sync
用一个额外的指针维护journal完成的时刻
- journal write (写入TXBegin和数据)
- journal commit (TXEnd + sync)
- 之后可以自由更新数据结构和指针 (完成后到达checkpoint)
- procfs中有jbd的统计信息
防止日志过长:
- circular log: 到达checkpoint后free
恢复崩溃:
从指针开始,向后重做journal中记录的操作
- (redo logging)
- 还有一种undo logging,记录操作的inverse (数据库中常用)
Journaling实现了文件系统操作的原子性
- 若干个block writes,要么全部发生,要么一个都不发生