Ch1 引论
- 编译器
- 读入以某种语言(源语言)编写的程序
- 输出等价的用另一种语言(目标语言)编写的程序
- 通常目标程序是可执行的
- 解释器
- 直接利用用户提供的输入, 执行源程序中指定的操作
- 不生成目标程序, 而是根据源程序的语义直接运行
- Java语言的处理结合的编译和解释
编译器的结构
- 编译器的结构: 分成分析部分和综合部分
- 分析部分(前端)
- 把源程序分解成组成要素, 以及相应的语法结构
- 使用这个结构创建源程序的中间表示
- 同时收集和源程序相关的信息, 存放到符号表
- 综合部分(后端)
- 根据中间表示和符号表信息构造目标程序
- 前端部分是机器无关的, 后端部分是机器相关的
- 分析部分(前端)
编译器的步骤
编译器可分为顺序执行的一组步骤:
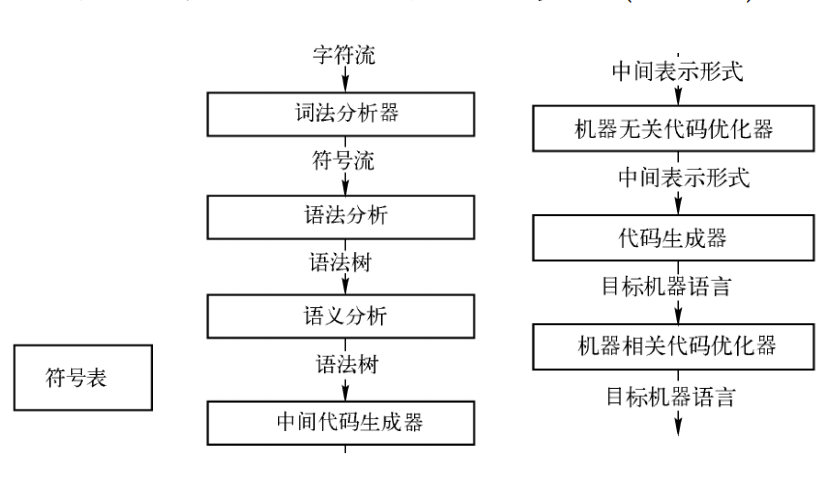
词法分析/扫描(Lexical analysis/scanning)
- 读入源程序的字符流, 输出为有意义的词素(Lexeme)
- < token-name, attribute-value>
- token-name由语法分析步骤使用
- attribute-value指向相应的符号表条目, 由语义分析/代码生成步骤使用
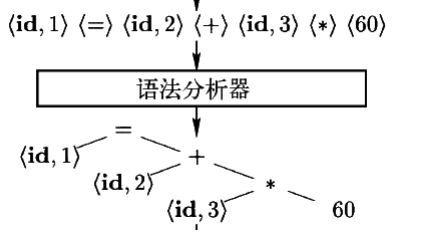
- 例子:
- position = initial + rate * 60
语法分析/解析 (Syntax analysis/parsing)
- 根据各个词法单元的第一个分量来创建树型的中间表 示形式,通常是语法树 (Syntax tree)
- 中间表示形式指出了词法单元流的语法结构
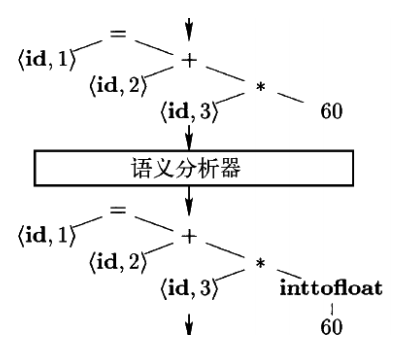
语义分析 (Semantic analysis)
- 使用语法树和符号表中的信息,检查源程序是否满足 语言定义的语义约束
- 同时收集类型信息,用于代码生成、类型检查、类型转换
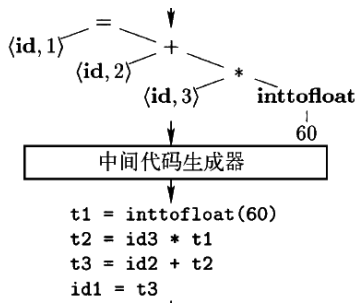
中间代码生成
- 根据语义分析输出,生成类机器语言的中间表示
- 三地址代码
- 每个指令最多包含三个运算分量
- t1 = inttofloat(60); t2 = id3 * t1; t3 = id2 + t2; …
- 很容易生成机器语言指令
中间代码优化
- 通过对中间代码的分析,改进中间代码的质量
- 更快、更短、能耗更低
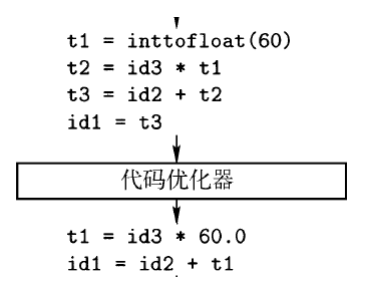
- 更快、更短、能耗更低
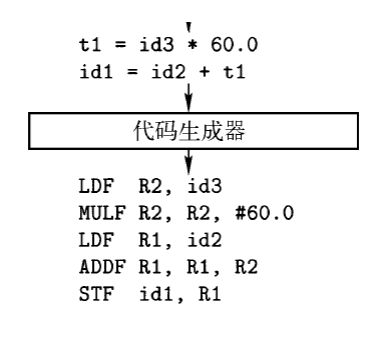
代码生成
- 把中间表示形式映射到目标语言
- 寄存器的分配
- 指令选择
其他概念
- 符号表管理
- 记录源程序中使用的变量的名字,收集各种属性
- 趟(Pass)
- 每趟读入一个输入文件,产生一个输出文件
- “步骤” (Phase) 是逻辑组织方式
- “趟”和具体的实现相关
- 编译器构造工具
- 扫描器 (Lex/Flex)、语法分析器 (Yacc/Bison)、语法制导的翻译引擎、…
程序设计语言的基础概念
- 静态/动态
- 静态: 支持编译器静态决定某个问题
- 动态: 只允许在程序运行时刻做出决定
- 作用域
- x的作用域指程序文本的一个区域,其中对x的使用都指向这个声明
- 静态作用域:通过静态阅读程序即可决定作用域
- 动态作用域
- 环境与状态
- 环境:是从名字到存储位置的映射
- 状态:从存储位置到它们值的映射
- 左值: 位置(寄存器or内存某位置), 右值: 具体的值
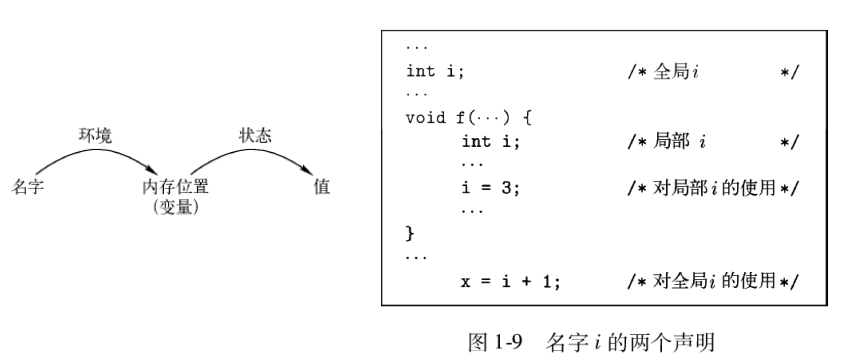
- 静态作用域和块结构
- C语言使用静态作用域
- C语言程序由顶层的变量、函数声明组成
- 函数内部可以声明变量 (局部变量/参数),这些声明的作用域 在它出现的函数内
- 一个顶层声明的作用域包括其后的所有程序
- 作用域规则基于程序结构,声明的作用域由它在程序中的位置决定
- 也通过public、private、protected进行明确控制
- C语言使用静态作用域